This post is a continuation of this tweet thread
Language deprecation for stacks can be a task if you are on VMs, added to that the confusion on what version of that stack runs, in your inventory if it's not small. Summarizing what we ended up doing to bring visibility & giving people the ability to migrate themselves (1/n)
— Tasdik Rahman (@tasdikrahman) January 29, 2021
Compute VM’s
Given the nature of VMs and how they are run and created in our compute infrastructure environment. Managing, upgrading and adding fixes to them becomes a task in itself. Given that there is no control plane to control the lifecycle of these VM’s, the task is manual at best even though there is automation to delete and create VMs on demand (more on the VM creation API which we created in a different post).
If the workloads were on kubernetes, the deprecation step is as simple as a simple deploy of the application, after the base images would have been updated with the necessary changes required to deprecate the language stack.
Given the confusion on which language stack version ran on which VM’s of our inventory, this only added to the problem statement. Which is clear in itself, that we have to deprecate a group of VM’s which are running a particular language stack without causing any disruption to the workloads running on them.
Where to start?
To begin with, the automation would need fixing to disallow the creation of the compute infrastructure with the language stack which is out for deprecation. This would help remove the moving target of VMs which would get created with the automation you have. Having a finite number helps reduce the effort at the end.
Creating the inventory
Along with that, the next natural step would be the creation of the inventory of which set of VM’s are running the version of language stack which you would want to deprecate.
If the number of VM’s are in a few hundreds combined for the org, one can simply check their IAC configuration which they would have checked into their git repo’s, which they had applied to create the infrastructure.
Manual for an effort, but for starters would work just fine due to the smaller number of VM’s.
In contrast, if the inventory of VM’s is running in thousands of VM’s, the same approach is impractical at best. Furthermore, the whole idea of maintaining the IAC for these set of VM’s is counter-intuitive given the amount of config which would have to be maintained.
Compute at present is created on demand. A dev needing a compute VM can simply go ahead and use proctor (our in house automation orchestrator) to create a VM for them. (More on this in this talk
But what about inventory? While creating the VM, we add tags (both on the configuration management tool, along with the cloud provider resource which is created)
This allows someone to query the VMs with regards to which team/group the VM belongs to. While creating the VMs if your current automation is missing the addition of the language version stack version which it is going to create the version with. Which also makes the whole job very simple in terms of just querying your configuration management tool to get your VM’s for the query you would like to give it. In our case, we didn’t have these tags for the language stack versions.
Which brings us to the situation, where it’s not clear on which VM’s are actually running which version of a language stack. As to the number of language stack versions running in the VM’s would vary as and when support for different versions would have been added over time.
How did we go about it? Given the number of VM’s, it was best to have this generated in an automated manner, simply because of the impracticality of this being tackled in a manner which involved someone checking this and creating it manually. Along with the fact that, the VM infrastructure would keep increasing over time, the data would go stale really quick.
As this was also something which would have to be repeated for another language stack/os version/etc again sometime in the future, it was best to have some sort of a repeatable and predictable process which could be leveraged to do this in a faster manner.
The solution as of now is an airflow job, which runs at a specific time frame, after the execution of which, the end result are a few artifacts which it creates/updates
The artifact in our case being, a google sheet which will have entries of all VM’s which are running the particular language stack, along with metadata for eg: ownership details, os version, production/integration, what kind of compute VM is it etc.
What the airflow job does, apart from this, is to keep updating a RDBMS with information similar to what it inserted in the google sheet.
The RDBMS got imported as a data source on grafana, on top of which we gave the end users the VM’s under their ownership for that particular language stack. This allowed them to have a simple interface to the VM set, without the need for them to know any internal details.
How does having different view layers for this inventory help?
The dev folks would simply look at the VM hostname/IP and replace it with the automation they are familiar with to create a new VM to be used in place with older VM, giving them the power to do the whole activity without getting blocked on anyone
To keep track of how many VM’s each product group/team’s progress, what we also ended up doing was, keep a track of the number of VM’s they had for that particular language stack at the end of each week.
This number, would be then sent to the teams/product groups as an email which is powered by another scheduled airflow job, along with a grafana dashboard for viewing the set of instance and docs required for doing the whole activity
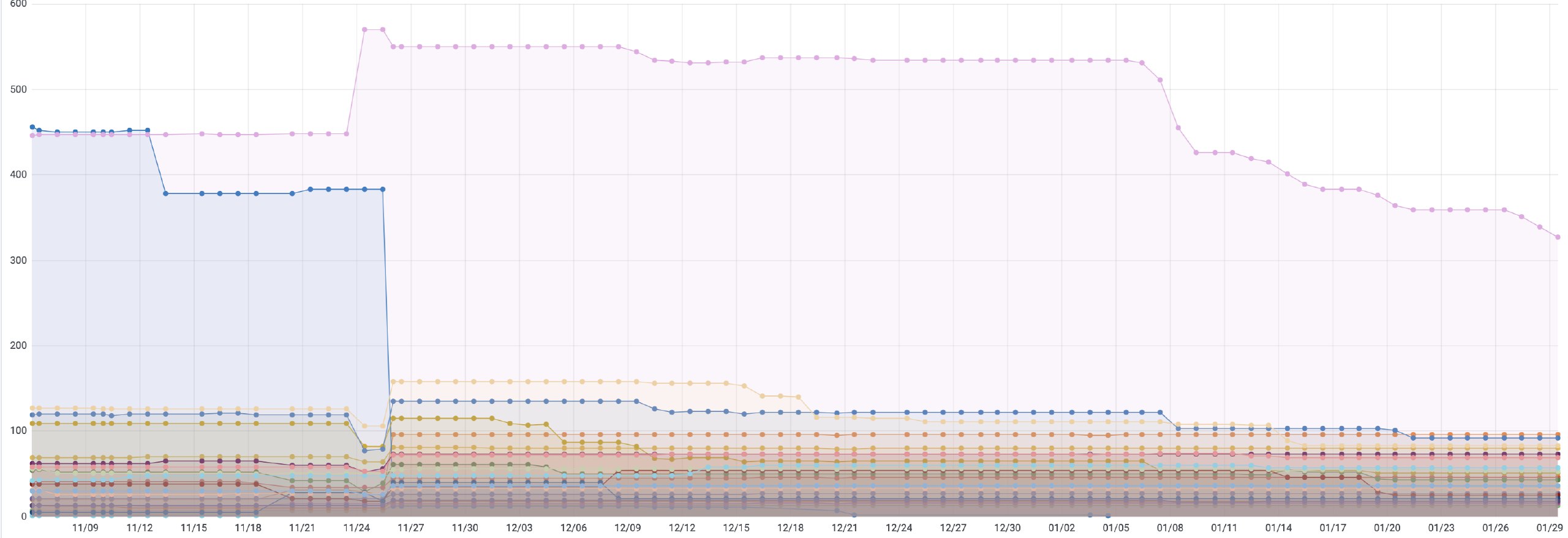
The following dashboard for example, shows the trend line for the number of VM’s on a particular language stack and their numbers over time for different teams/product groups
More on the automation used
Coming back to the airflow automation job specifics, the job which creates/updates the google sheet and inserts VM details to the RDBMS.
It makes use of the configuration management tool’s language specific client which is used in the script, to first filter the VM’s based on a specific automation template which gets attached to the VM when it gets registered to the configuration management tool.
This helps first sort the VMs which would be running some version of the language stack. What the script does next is, ssh into these VM list in batch and pluck out the details of the language stack by running a command which would be specific to the language stack
Which would then blurt out the version information, the script captures this information from the VM and logs out. A few other helper commands are run as part of the whole script, which would pluck out the metadata relevant and create/update the artifacts necessary.
The helper library created here, is flexible enough to take input in the form of the query which you would want to run on the VM to capture the relevant information, which helps in future inventory management.
Would love to hear what you folks do for this repetitive chore and how you do it.
If you liked what you read here, I have written a bit more about how we did the same for containers here